VMware部署Hadoop集群
题目
第二部分是实践部分,要求学生使用虚拟机部署5台Linux服务器, 实现Linux服务器集群,并在Linux服务器集群上部署hadoop服务器。
具体要求如下:
- 使用纯净的centos7操作系统。其他软件均从网上下载安装
- 安装步骤写清楚。附上必要的操作流程和截图。
- 如果在安装过程中产生问题,在报告内进行描述并给出解决方案。
- 具体操作过程可以参考网上的操作流程,但是不允许直接抄袭!
实验环境
这里是博主的实验环境,仅供参考。
- VMware Workstation 17 Pro
- Windows 11 22H2 22621.1555 x64 企业版
实验步骤
参考:2023新版黑马程序员大数据入门到实战教程,大数据开发必会的Hadoop、Hive,云平台实战项目全套一网打尽
注意!我这只讲需要注意的配置项,默认的配置项不指出。
安装 VMware
由于先前实验中已有安装 VMware 的步骤,这里就不再赘述了。
下载 CentOS 7
推荐在清华源下载,速度较快。
下载地址:https://mirrors.tuna.tsinghua.edu.cn/centos/7.9.2009/isos/x86_64/CentOS-7-x86_64-Minimal-2009.iso
创建虚拟机
起名按自己认得的规律来就行,这里我就用了 hadoop-1、hadoop-2、hadoop-3、hadoop-4、hadoop-5。
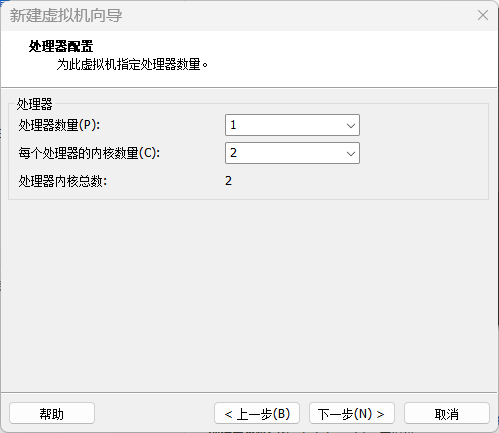
处理器配置为 2 核心,内存配置为 2 GB。
网络类型配置为 NAT 。
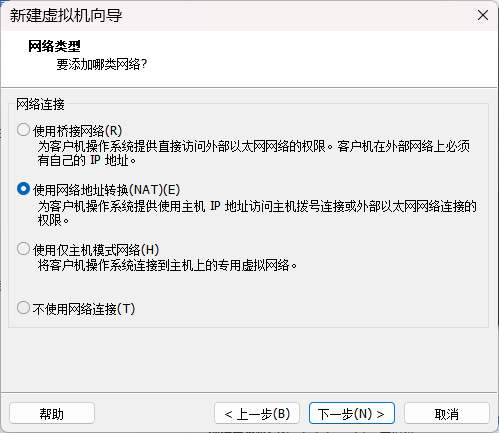
磁盘空间配置为 20 GB。

在虚拟机设置将 CD/DVD 设备连接到 ISO 文件。
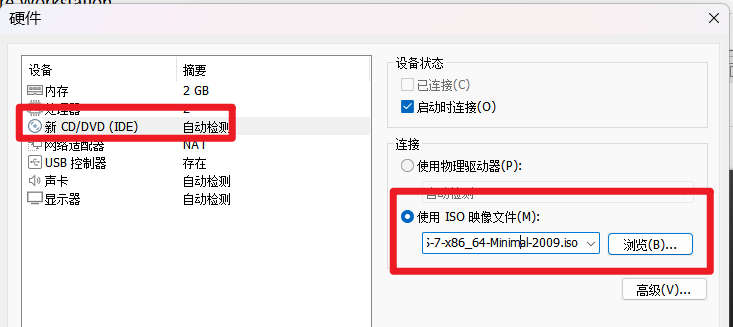
安装 CentOS 7
启动虚拟机,进入安装界面。
选择安装位置,进去后直接点击 Done 即可。

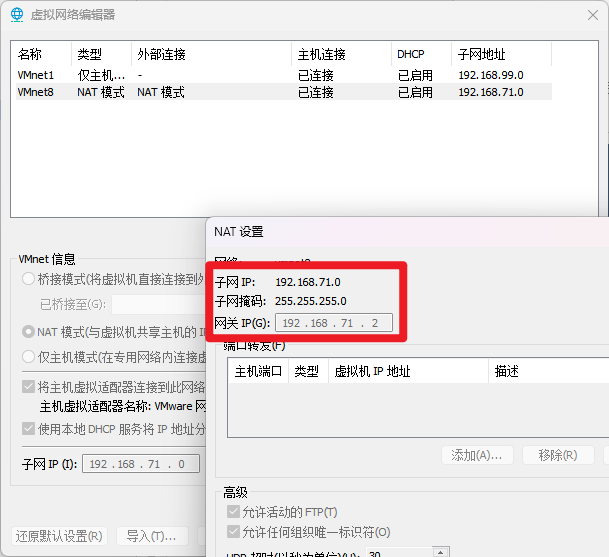
设置静态ip地址,这里要和虚拟网络管理器的NAT网络匹配才行。
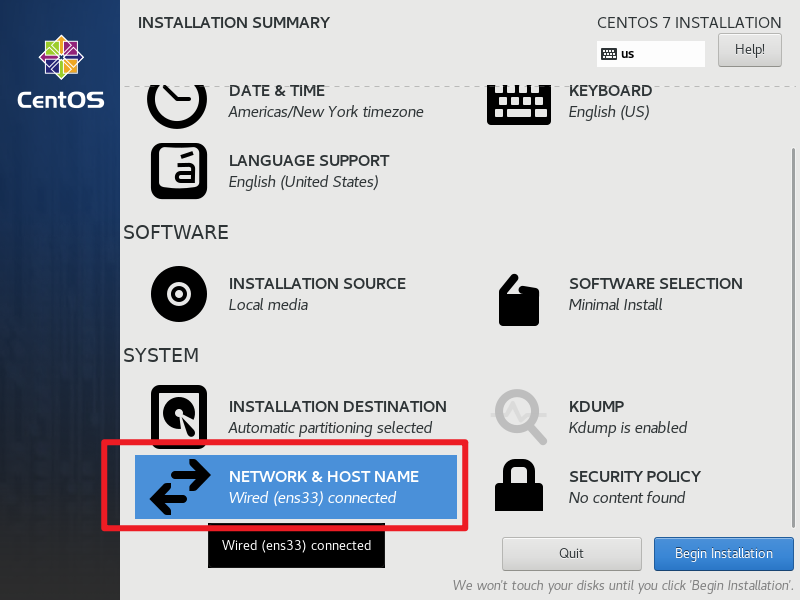

设置主机名。
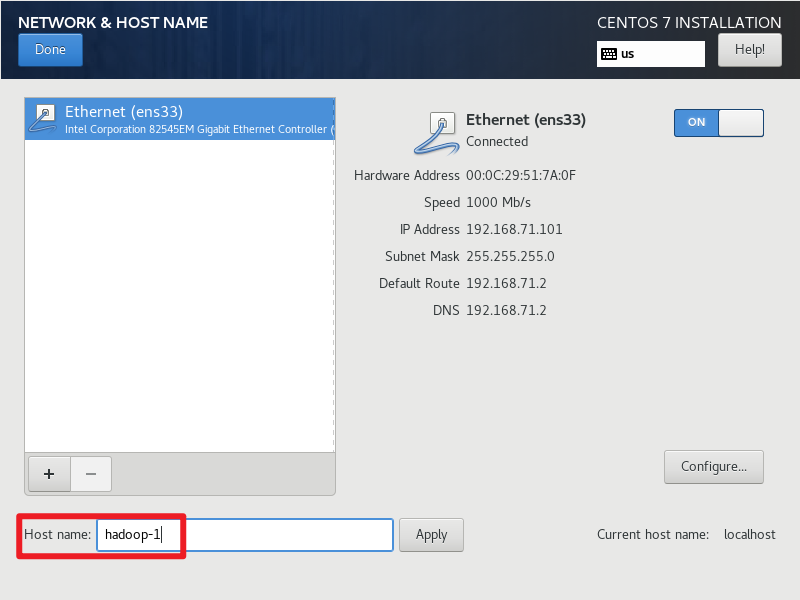
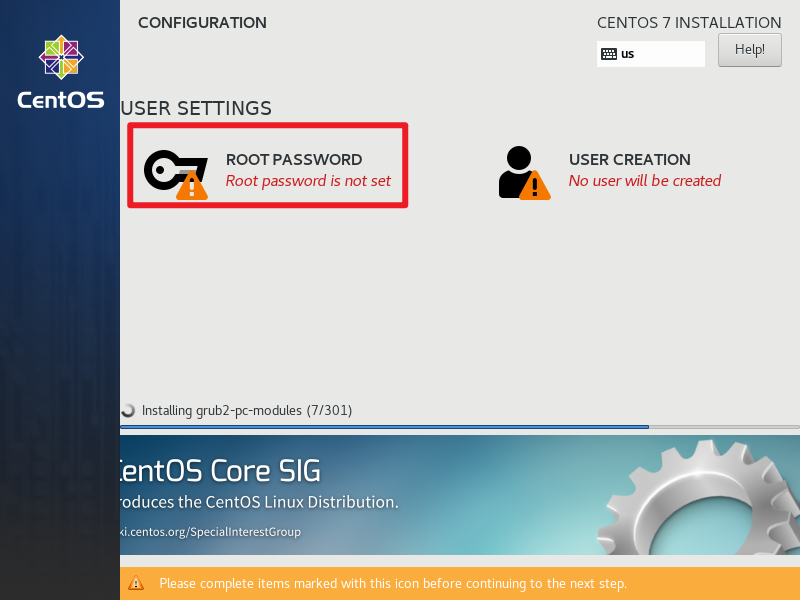
设置 root 密码。
重启虚拟机,进入系统。

配置基础环境
首先用 ssh 连接到虚拟机。
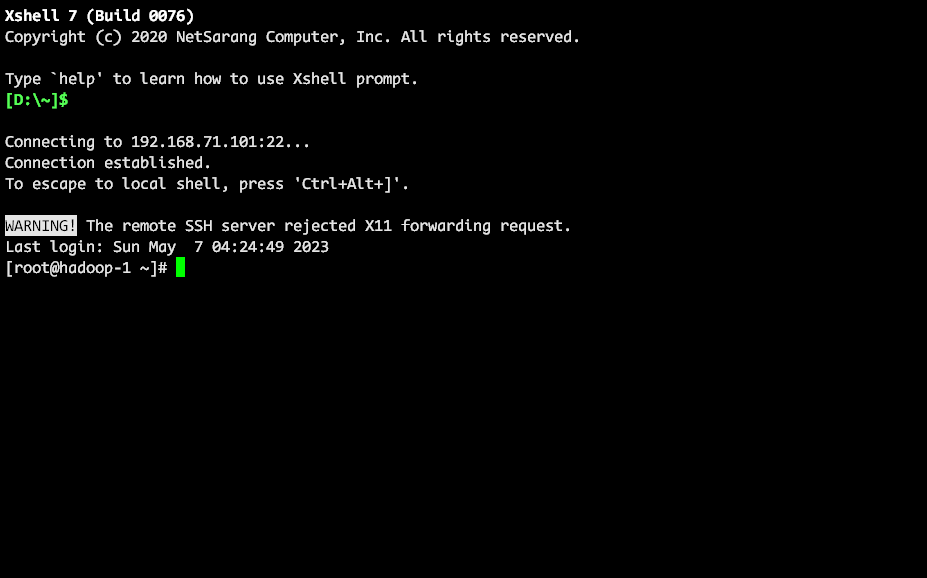
后面很多就是输命令的部分了,我尽量少使用需要交互的命令吧,这样我来说也是方便一点。
安装 wget
yum install -y wget
安装 JDK
yum install -y java-1.8.0-openjdk-devel
java -version
echo "export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk" >> /etc/profile
echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile
source /etc/profile
我感觉这一步可能是多余的,因为后续 Hadoop 自己也要配 JAVA_HOME 这个环境变量, 但是网上教程都有,我这里先配上吧,如果大家证实是不需要的,我再删掉。
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
关闭 SELinux
vim /etc/selinux/config
将 SELINUX=enforcing 改为 SELINUX=disabled 。
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
setenforce 0
安装 ntp 服务
yum install -y ntp
ntpdate -u ntp.aliyun.com
systemctl start ntpd
systemctl enable ntpd
timedatectl set-timezone Asia/Shanghai
配置主机名解析
echo "192.168.71.101 hadoop-1" >> /etc/hosts
echo "192.168.71.102 hadoop-2" >> /etc/hosts
echo "192.168.71.103 hadoop-3" >> /etc/hosts
echo "192.168.71.104 hadoop-4" >> /etc/hosts
echo "192.168.71.105 hadoop-5" >> /etc/hosts
安装 Hadoop
创建 hadoop 用户
useradd hadoop
echo "123456" | passwd --stdin hadoop
下载 Hadoop
su - hadoop
wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz
tar -zxvf hadoop-3.3.5.tar.gz
mv hadoop-3.3.5 hadoop
cd hadoop
配置 Hadoop
计划部署一个 5 节点的 Hadoop 集群,分配如下表所示。
| 节点名称 | IP 地址 | 角色 |
|---|---|---|
| hadoop-1 | 192.168.71.101 | NameNode、DataNode、SecondaryNameNode |
| hadoop-2 | 192.168.71.102 | DataNode |
| hadoop-3 | 192.168.71.103 | DataNode |
| hadoop-4 | 192.168.71.104 | DataNode |
| hadoop-5 | 192.168.71.105 | DataNode |
配置worker节点
cd etc/hadoop
echo "hadoop-1" > workers
echo "hadoop-2" >> workers
echo "hadoop-3" >> workers
echo "hadoop-4" >> workers
echo "hadoop-5" >> workers
配置环境变量
echo "export HADOOP_HOME=/home/hadoop/hadoop" >> hadoop-env.sh
echo "export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk" >> hadoop-env.sh
echo "export HADOOP_CONF_DIR=\$HADOOP_HOME/etc/hadoop" >> hadoop-env.sh
echo "export HADOOP_LOG_DIR=\$HADOOP_HOME/logs" >> hadoop-env.sh
配置 core-site.xml
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
配置 hdfs-site.xml
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>hadoop-1,hadoop-2,hadoop-3,hadoop-4,hadoop-5</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dn</value>
</property>
</configuration>
创建目录
mkdir -p ~/data/nn ~/data/dn
配置环境变量
echo "export HADOOP_HOME=/home/hadoop/hadoop" >> ~/.bashrc
echo "export PATH=\$PATH:\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin" >> ~/.bashrc
source ~/.bashrc
准备 SSH 免密登录
参考:Linux免密大法好 ssh-copy-id 和 expect 免交互输入脚本
安装 expect。
yum install -y expect tcl-devel
编写免交互脚本。
#!/usr/bin/expect
set timeout 10
set username [lindex $argv 0]
set password [lindex $argv 1]
set hostname [lindex $argv 2]
spawn ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub $username@$hostname
expect {
#first connect, no public key in ~/.ssh/known_hosts
"Are you sure you want to continue connecting (yes/no)?" {
send "yes\r"
expect "password:"
send "$password\r"
}
#already has public key in ~/.ssh/known_hosts
"password:" {
send "$password\r"
}
"Now try logging into the machine" {
#it has authorized, do nothing!
}
}
expect eof
赋予执行权限。
chmod +x auto_ssh.sh
编写执行脚本。
#!/bin/bash
hosts=(
hadoop-1
hadoop-2
hadoop-3
hadoop-4
hadoop-5
)
for host in ${hosts[@]}
do
./auto_ssh.sh hadoop '123456' $host
done
配置其他节点
关闭虚拟机
shutdown -h now
拍摄快照
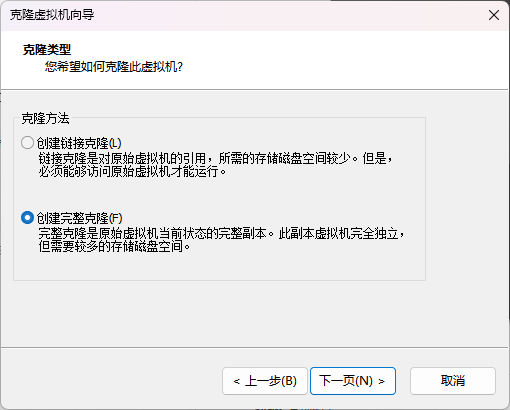
克隆虚拟机

选择 创建完整克隆 。
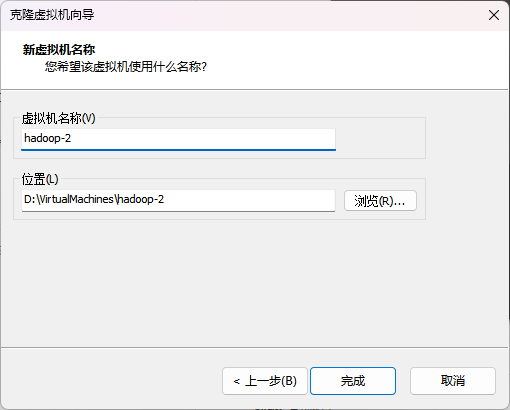
分别改名为 hadoop-2、hadoop-3、hadoop-4、hadoop-5。
修改网卡 MAC 地址


修改主机名
分别修改 hadoop-2、hadoop-3、hadoop-4、hadoop-5 的主机名。
hostnamectl set-hostname hadoop-2
修改 IP 地址
分别修改 hadoop-2、hadoop-3、hadoop-4、hadoop-5 的 IP 地址。
| 节点名称 | IP 地址 |
|---|---|
| hadoop-2 | 192.168.71.102 |
| hadoop-3 | 192.168.71.103 |
| hadoop-4 | 192.168.71.104 |
| hadoop-5 | 192.168.71.105 |
sed -i 's/IPADDR=.*/IPADDR=192.168.71.102/' /etc/sysconfig/network-scripts/ifcfg-ens33
systemctl restart network
配置 SSH 免密登录
ssh-keygen -t rsa -b 4096
bash ./auto_ssh_run.sh
启动 Hadoop
所有节点准备好后是这样的。

格式化 NameNode
hadoop namenode -format
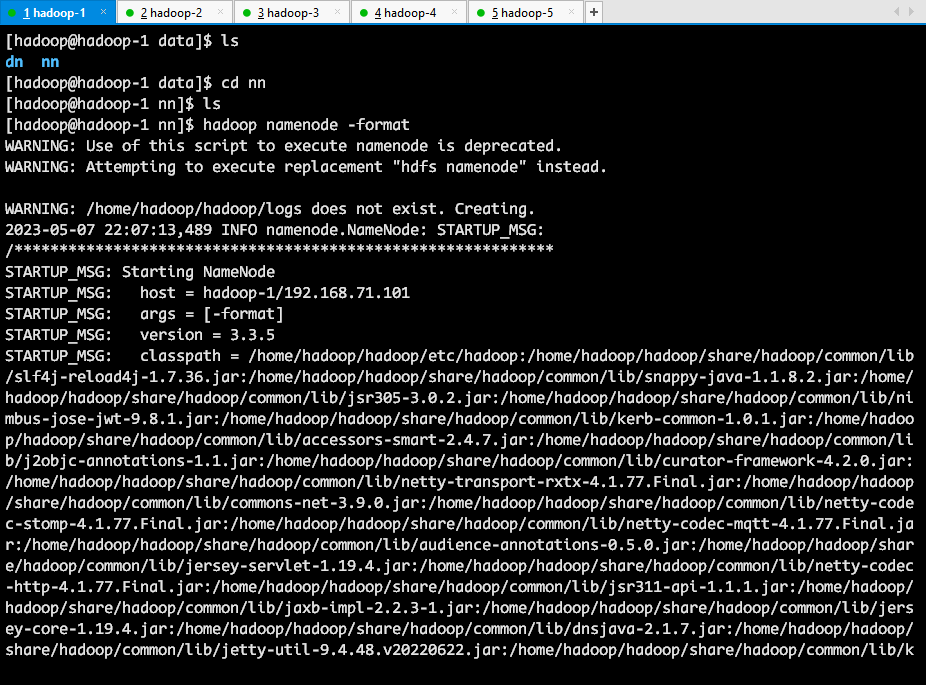
可以看到 nn 目录下生成了文件。
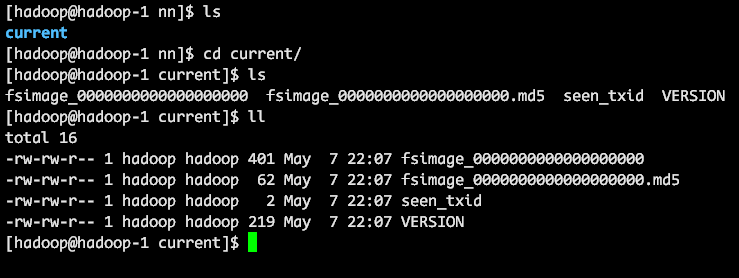
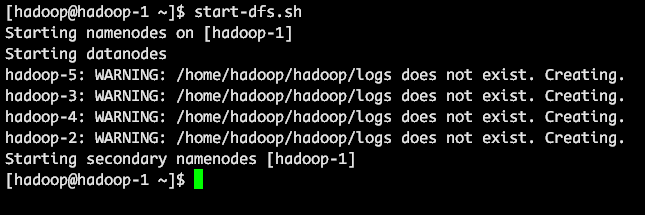
启动 Hadoop
start-dfs.sh
查看 Hadoop 状态
执行 jps 命令查看当前运行的 Java 进程。
jps





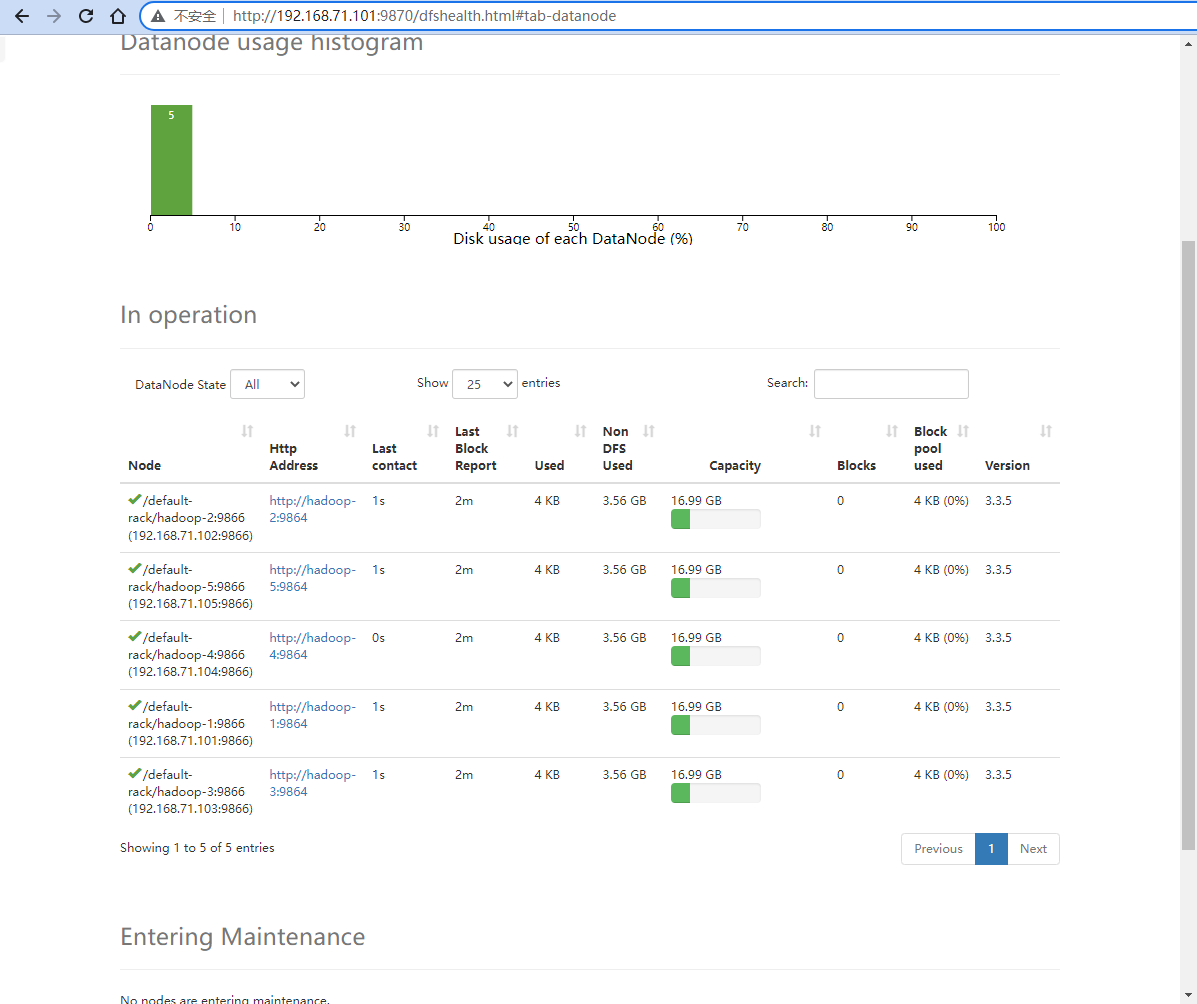
访问 http://192.168.71.101:9870/ 可以看到 NameNode 的状态。
可以看到有 5 个 DataNode。
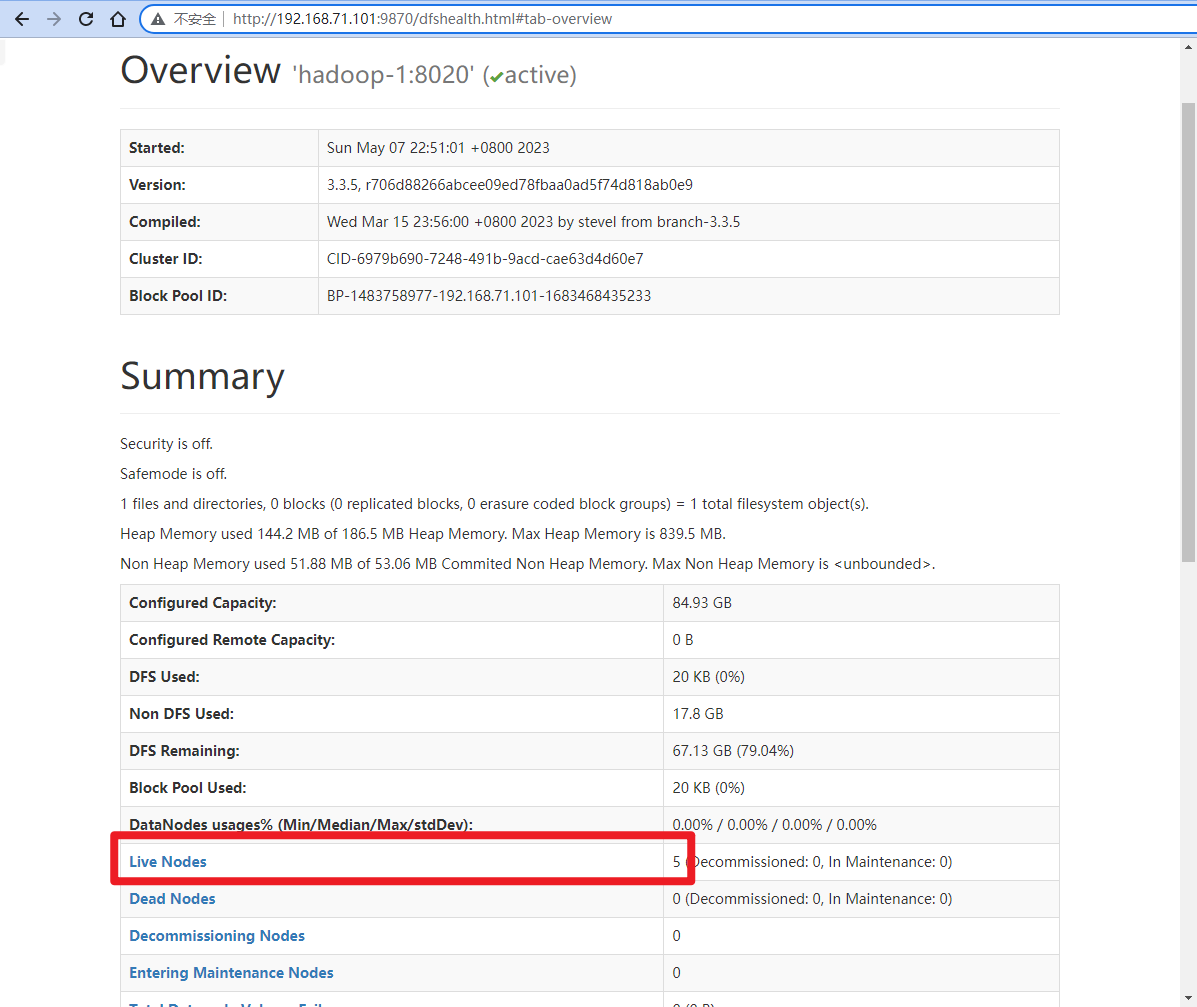
点击 Live Nodes 可以看到 5 个 DataNode 的状态。